Working Effectively With Legacy SQL
Kevin Feasel (@feaselkl)https://csmore.info/on/legacysql
Who Am I? What Am I Doing Here?



What Is Legacy Code?
Neutral connotations:
- Code I inherited
- Older code I need to maintain
Negative connotations:
- Code without unit tests (Michael Feathers)
- "Rotten" code (not well maintained)
- Code stuck on an older/obsolete platform
What Is Legacy Code?
My working definition is "rotten" code: code which has not been maintained very well. This code often lacks tests, but the key characteristic is the amount of pain necessary to make changes.
Motivation
Legacy SQL will de-motivate you over time. You will spend too much time debugging terrible procedures. In order to fulfill even simple business requests, you will change lots of difficult code, including code you don't even know is obsolete. Even after you leave, your successor will curse your name.
Older code doesn't need to be legacy code. Older code does need TLC, however.
Agenda
- Prerequisites
- SQL Formatting
- Simplify Your Code
- Simplify Your Design
- Remove Obsolete Code
- Modernize Your Code
- Improve Durability and Visibility
Source Control
You need source control for your SQL code. Source control gives you the ability safely to experiment. If your experiment fails, roll back your changes.
Use whatever source control system your developers are using, which is probably something involving Git.
Repeatble, Working Tests
Object-oriented languages have fully-featured test frameworks like NUnit to create unit tests. Developers can break apart small sections of functionality and test those sections controlling for that code's depdendencies.
T-SQL has a very limited version of database unit and integration testing. The most popular tools for these kinds of tests are tSQLt and Visual Studio database test projects.
Agenda
- Prerequisites
- SQL Formatting
- Simplify Your Code
- Simplify Your Design
- Remove Obsolete Code
- Modernize Your Code
- Improve Durability and Visibility
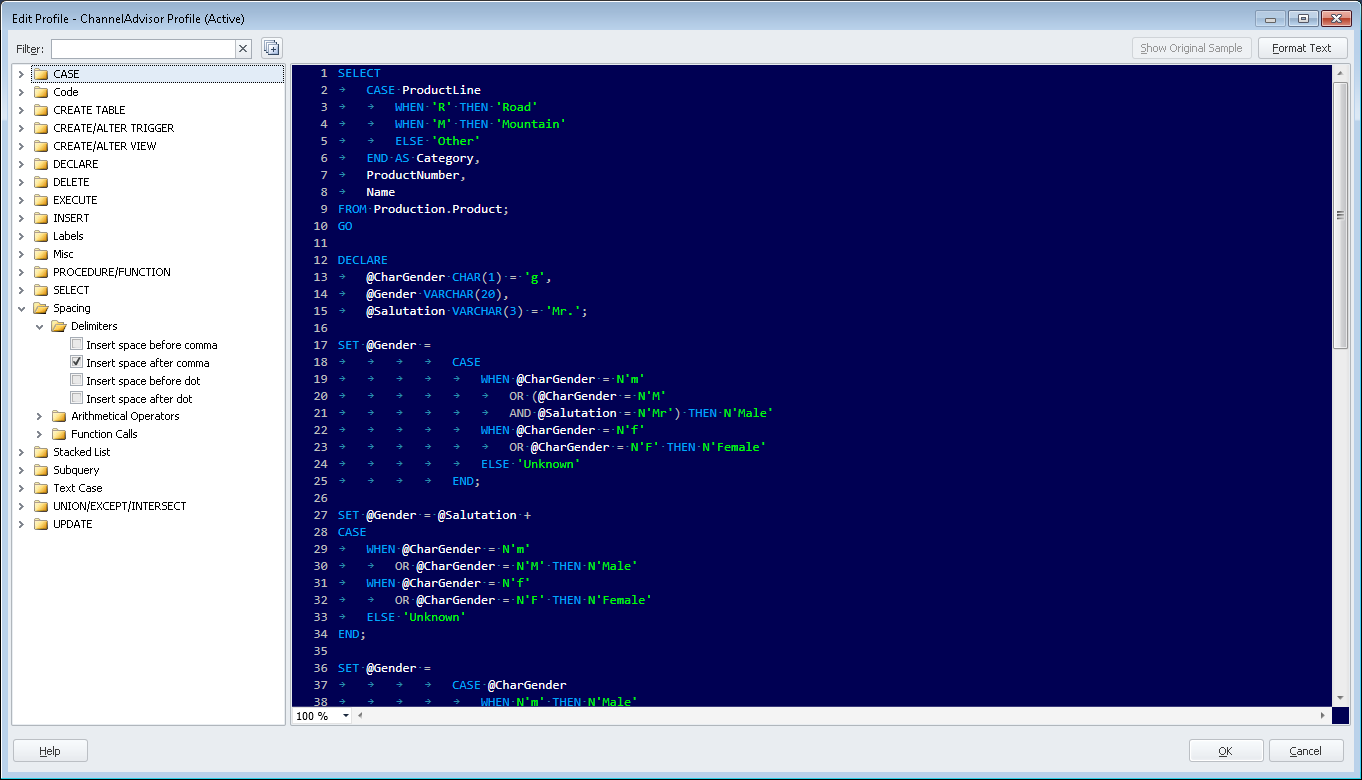
Format Your SQL
Formatting SQL is the lowest-risk form of refactoring, as you aren't making any logical code changes. If you format your SQL well, however, you can make your code more readable. Readable code is (potentially) understandable code.
Code is for humans as much as it is for compilers and interpreters!
Demo Time
Benefits from Formatting
- Lower risk of bugs due to misunderstanding code
- Lower risk of bugs due to forgetfulness (e.g., nested IF statements)
- Faster and easier maintenance
- The process helps you understand the code better
- Formatting holy wars (okay, not a benefit)
Consistent Casing
Capital Letters for Keywords
Consistent Indentation Levels
One Identifier Per Line
Use Spacing to Clarify Intent
Save Time with Tools
Agenda
- Prerequisites
- SQL Formatting
- Simplify Your Code
- Simplify Your Design
- Remove Obsolete Code
- Modernize Your Code
- Improve Durability and Visibility
Simplify Your Code
Simple is better than complex.
Complex is better than complicated.
A few examples of complicated code:
- Cursors and WHILE loops generating and executing dynamic SQL
- Chains of stored procedures with temp tables holding state
- Unrepeatable processes which kick off other processes which...
- Deeply nested IF statements
Simplify Your Code
We will now look at a series of methods to simplify code.
- Use the APPLY operator to simplify calculations
- Use static SQL in place of dynamic SQL
- Turn cursors and WHILE loops into set-based statements
- Simplify filters
- Simplify overall procedure design
DEMO TIME!
Agenda
- Prerequisites
- SQL Formatting
- Simplify Your Code
- Simplify Your Design
- Remove Obsolete Code
- Modernize Your Code
- Improve Durability and Visibility
Simplify Your Design
Once we have solid tests in place, we can look at refactoring entire designs instead of simply refactoring code within a single procedure.
This type of scenario will be most common if you have nested stored procedures. Then, treat the internal procedures as the equivalent of private methods and refactor around a contract.
Retain your outward-facing procedures' input and output signatures, and focus mostly on refactoring those "private" procedures.
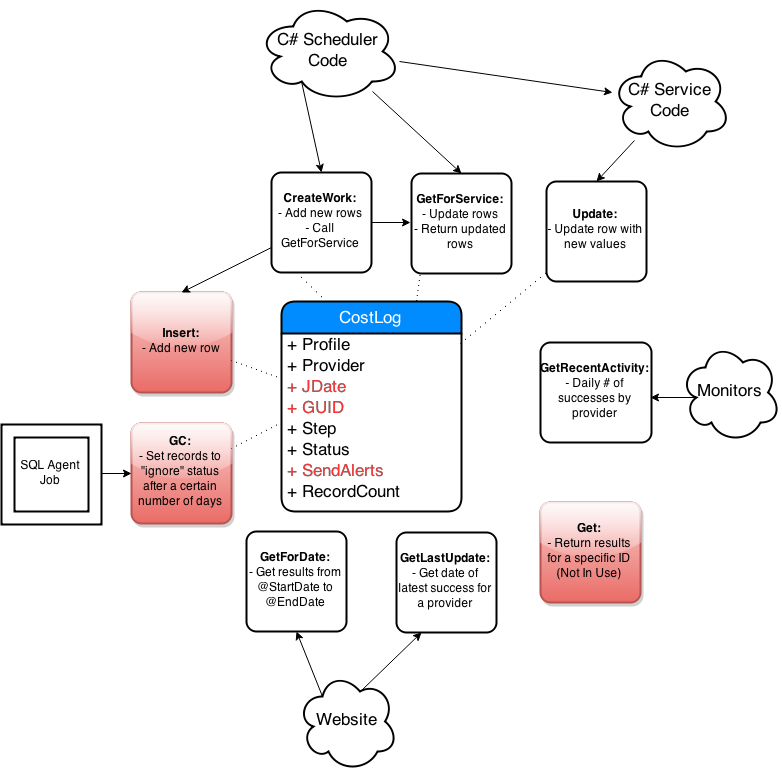
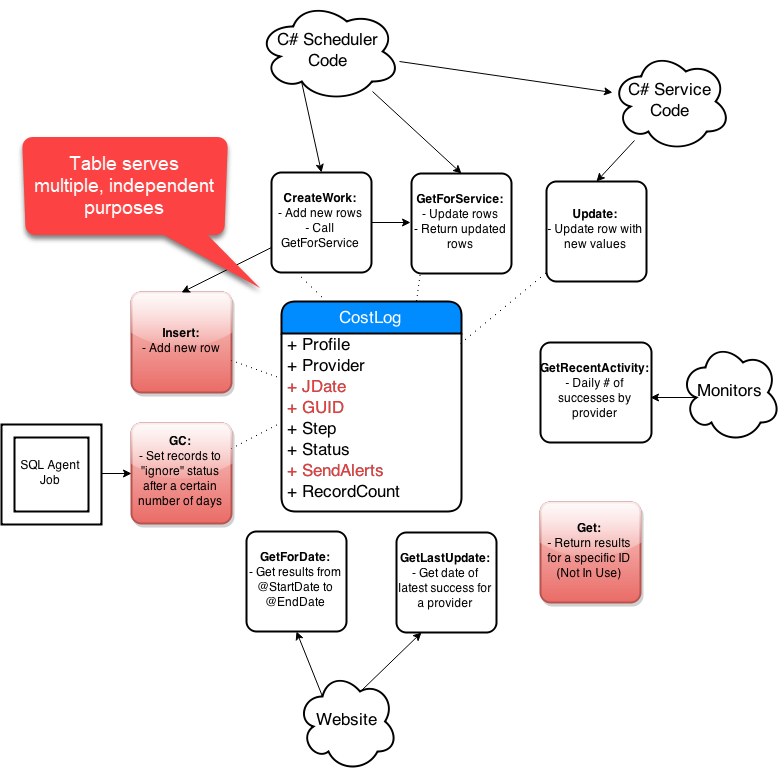
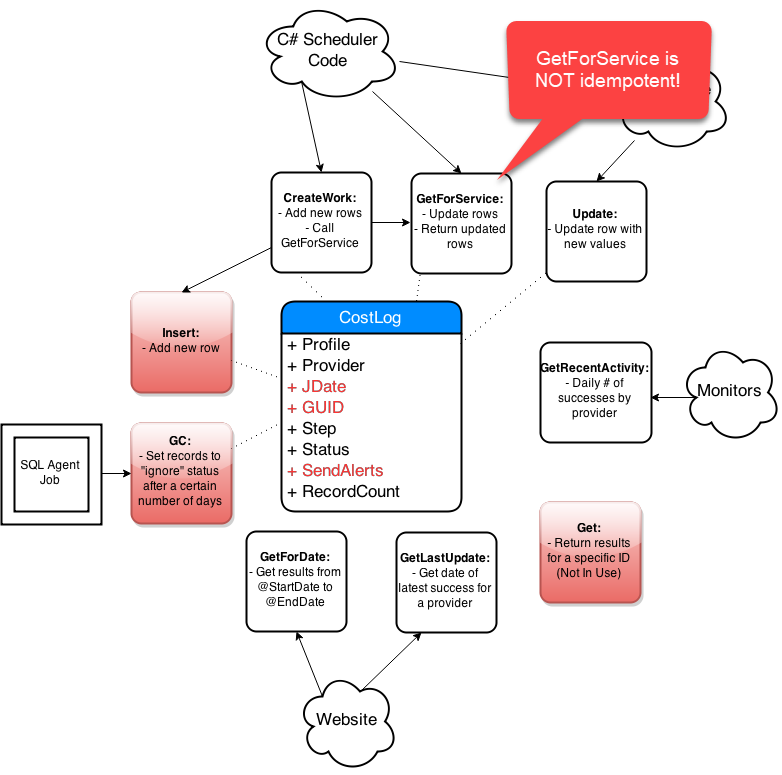
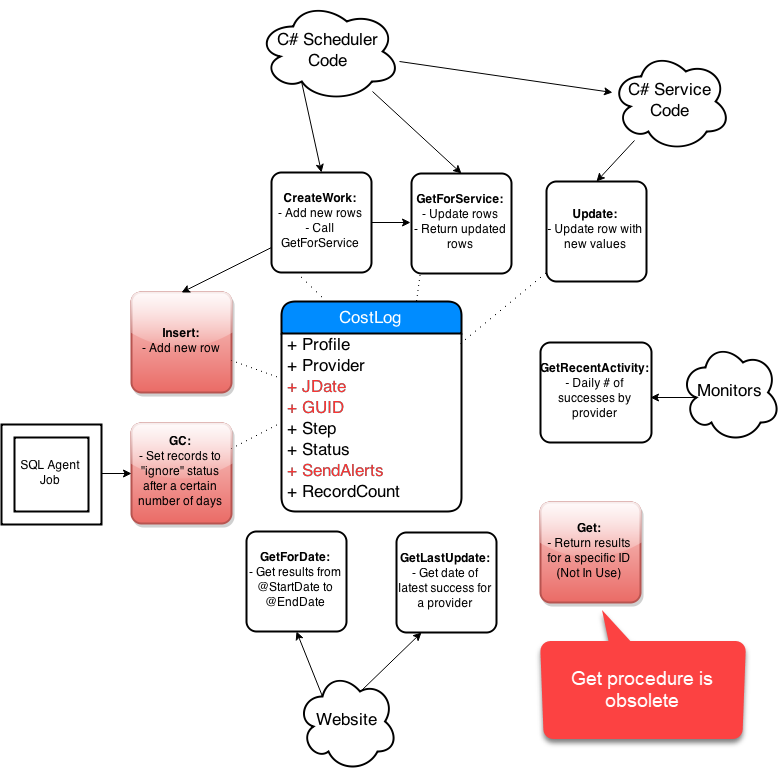
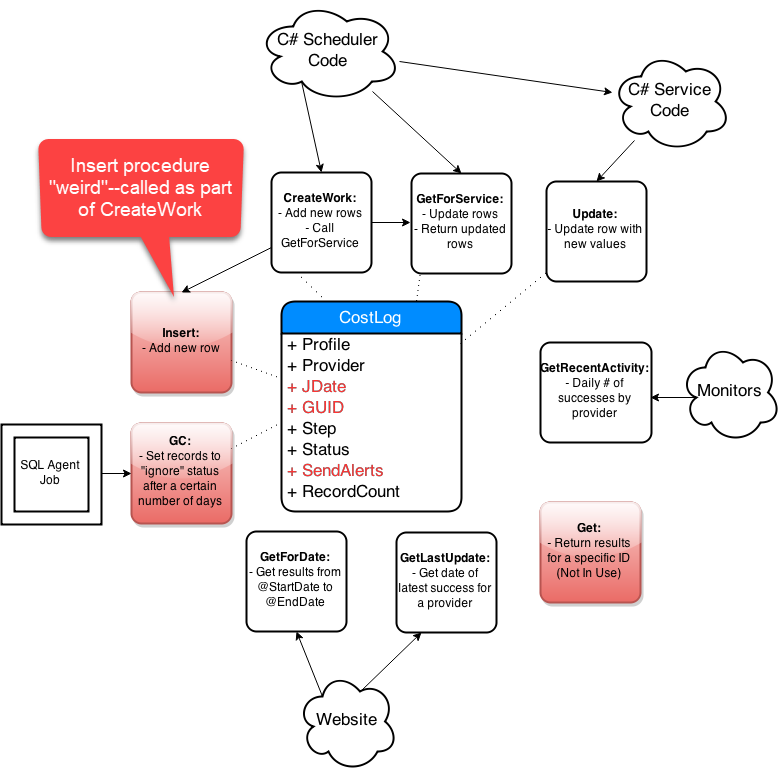
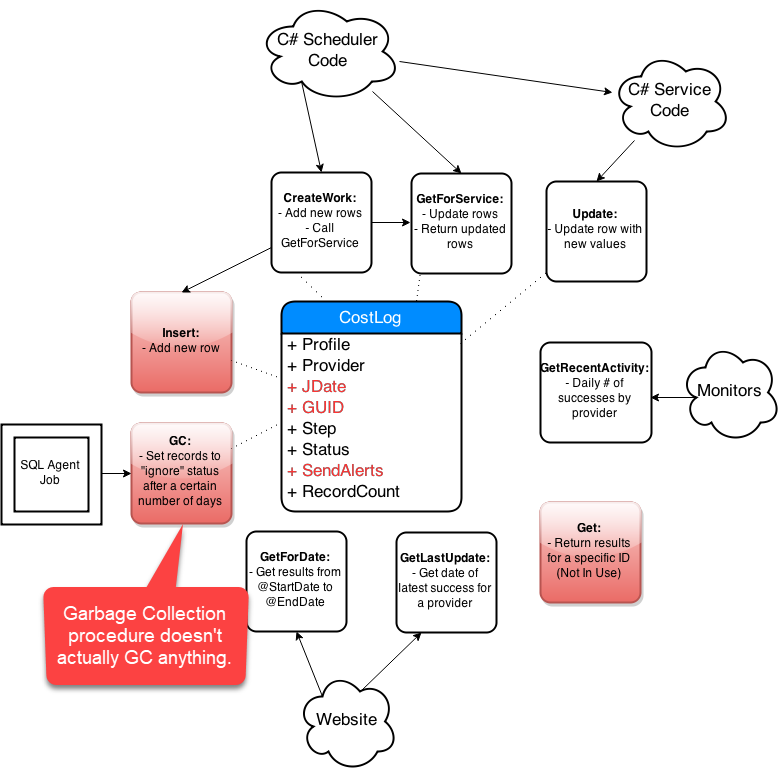
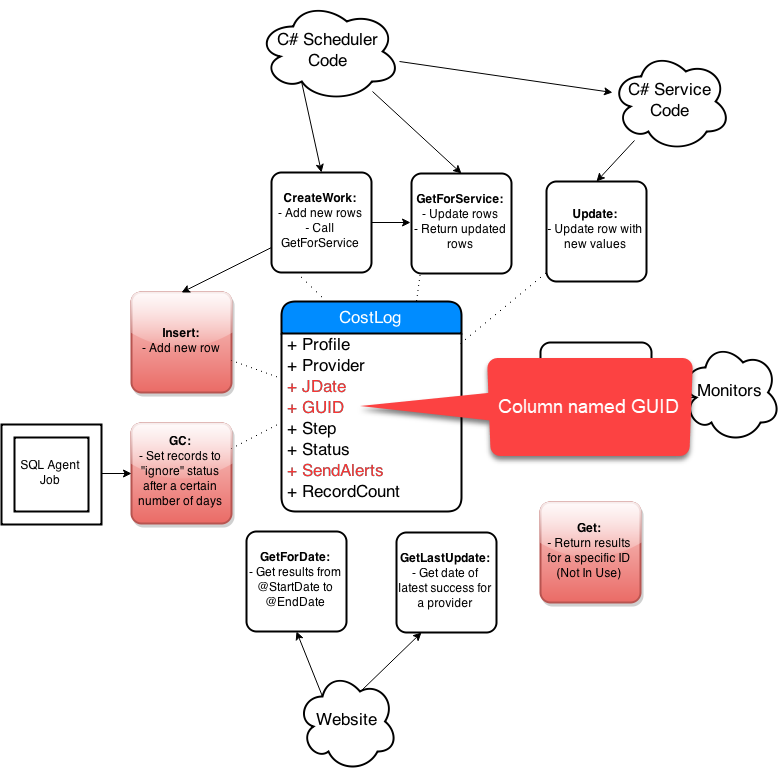
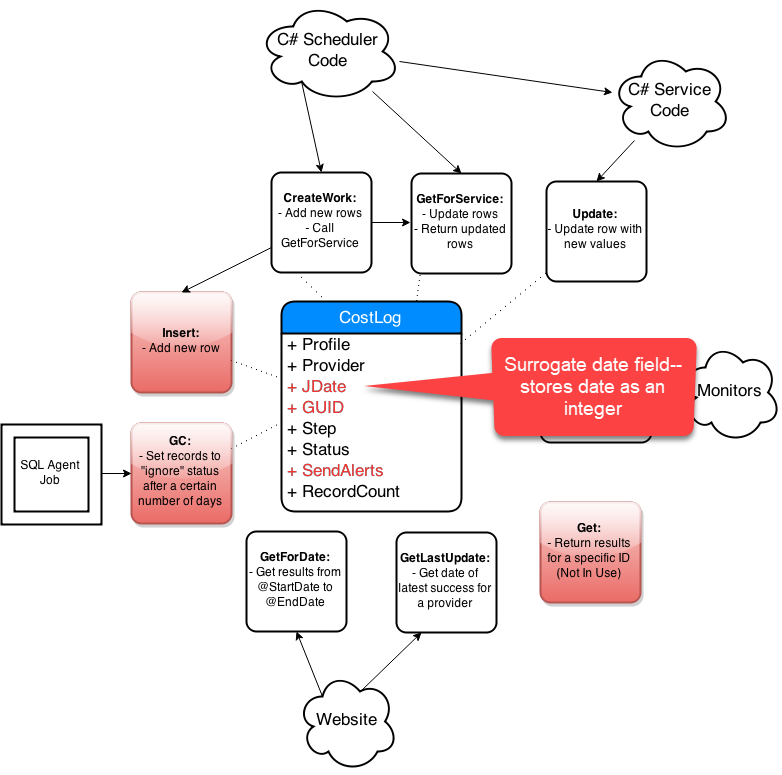
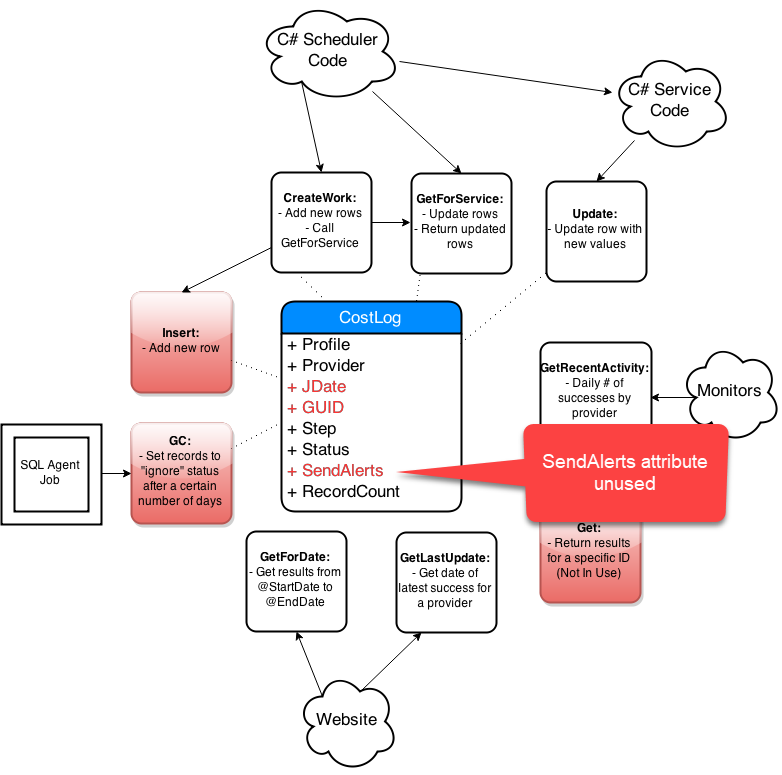
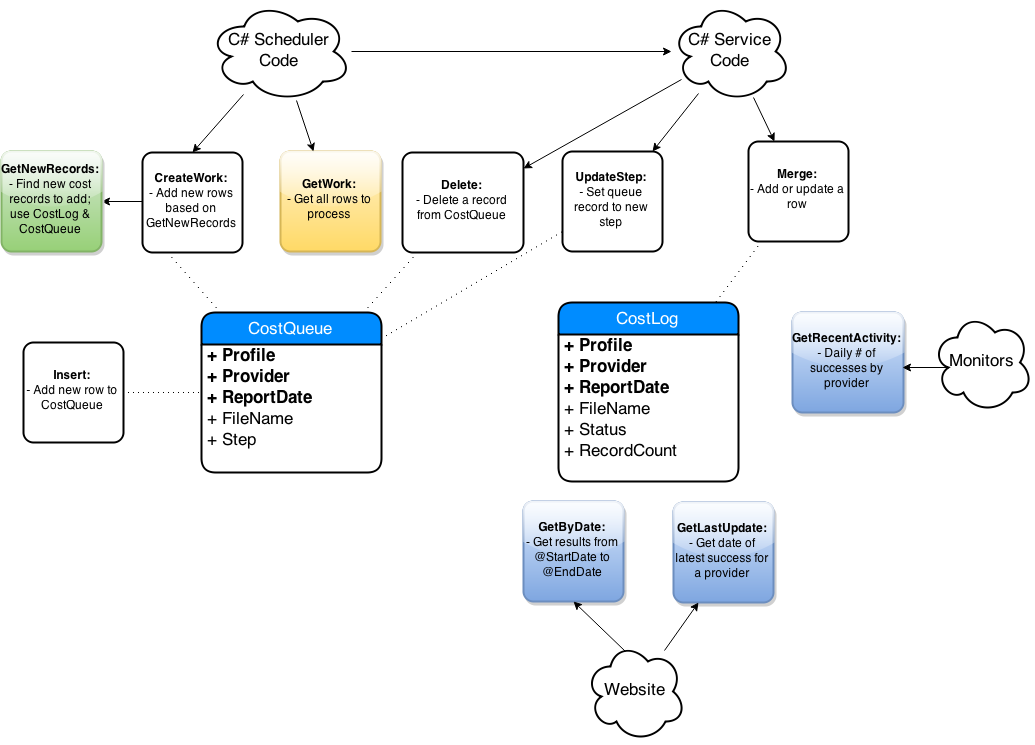
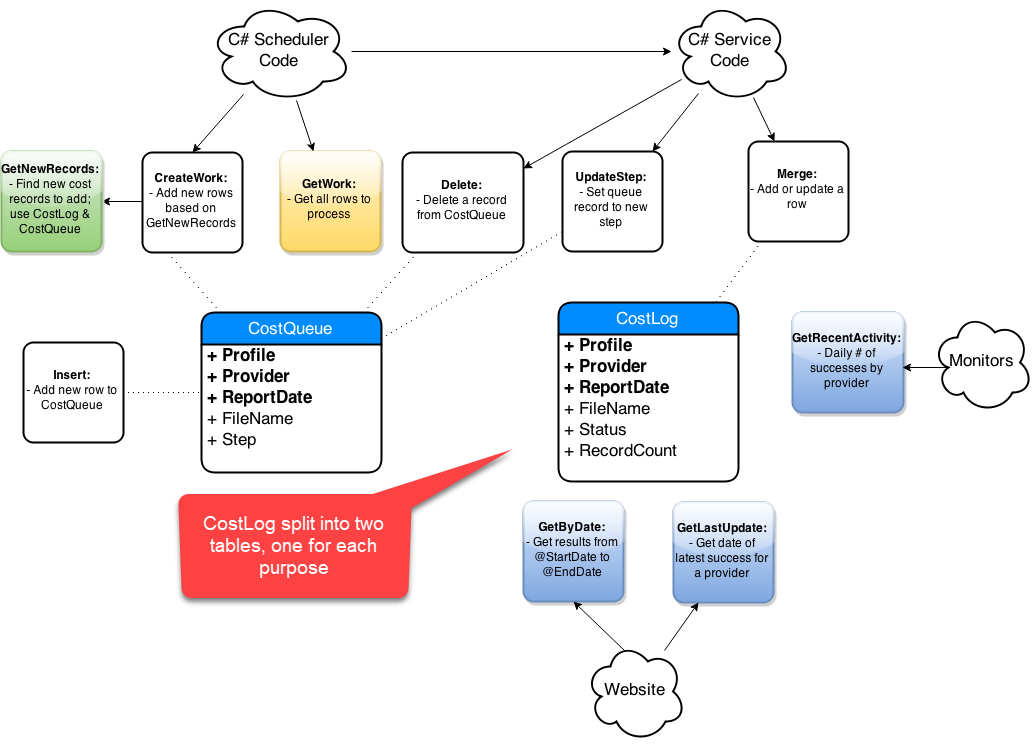
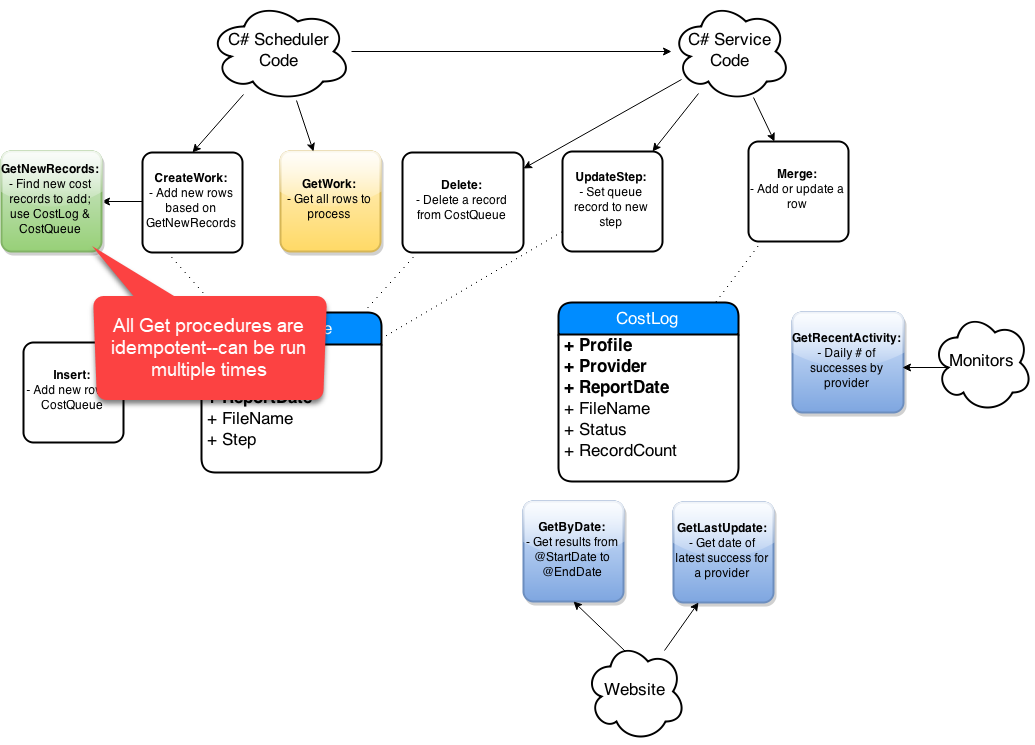
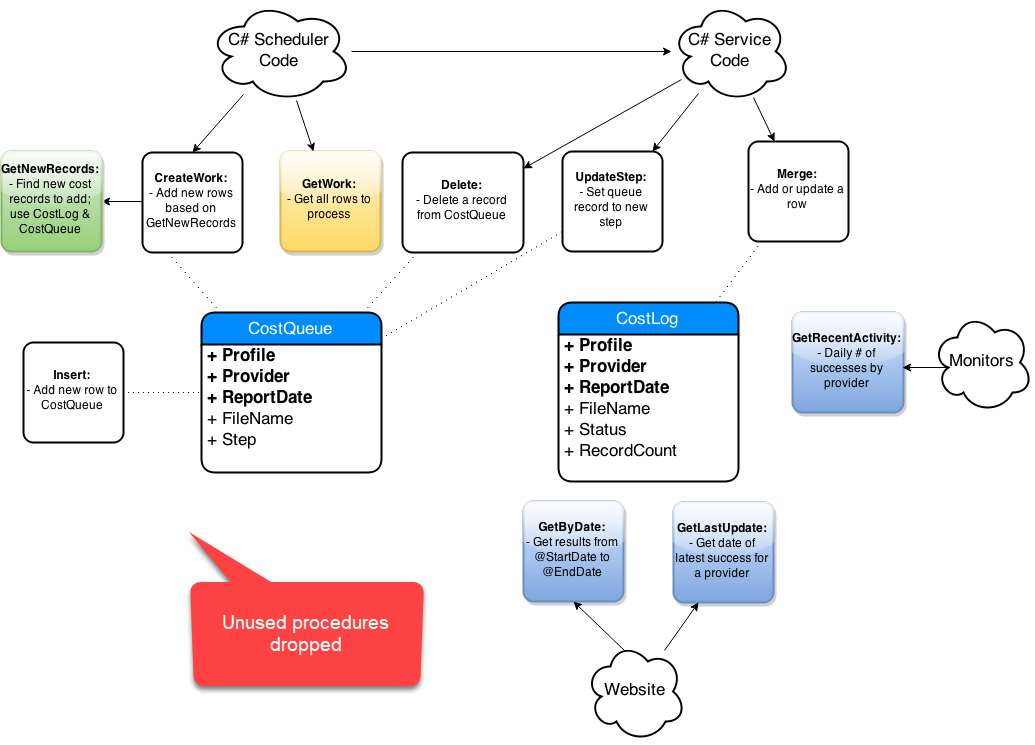
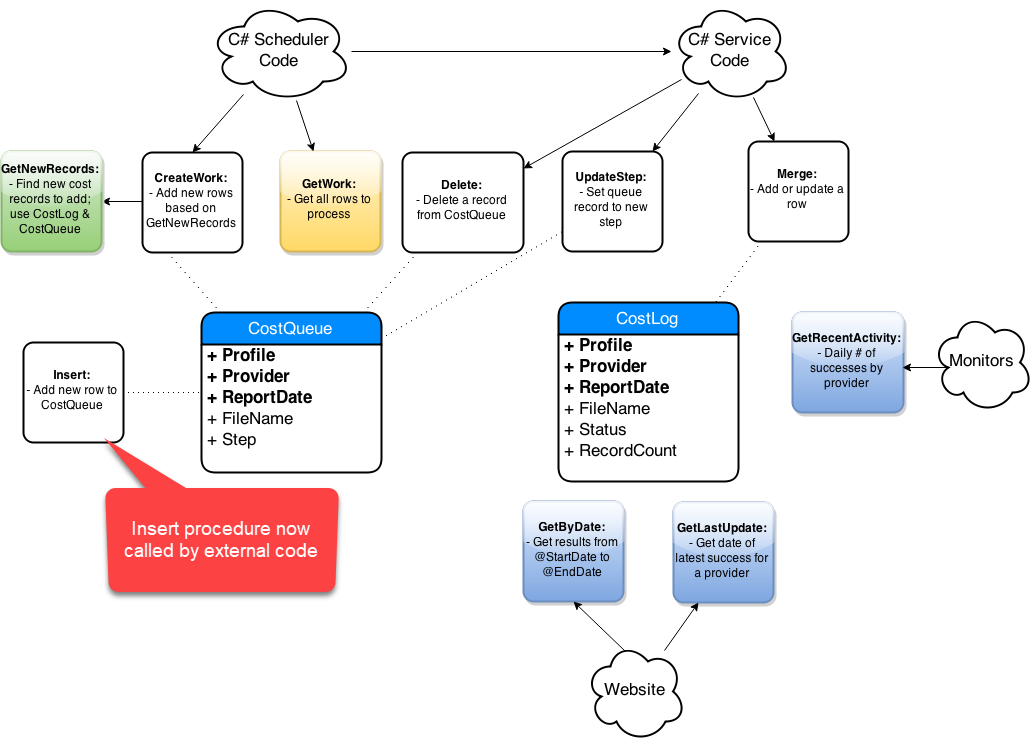
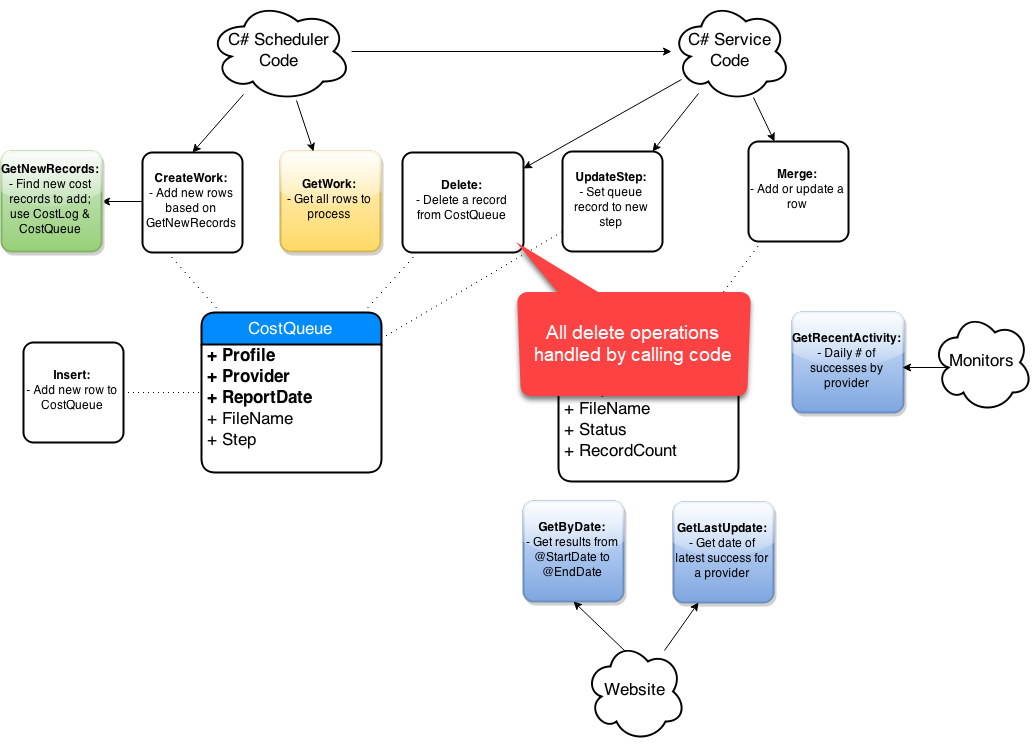
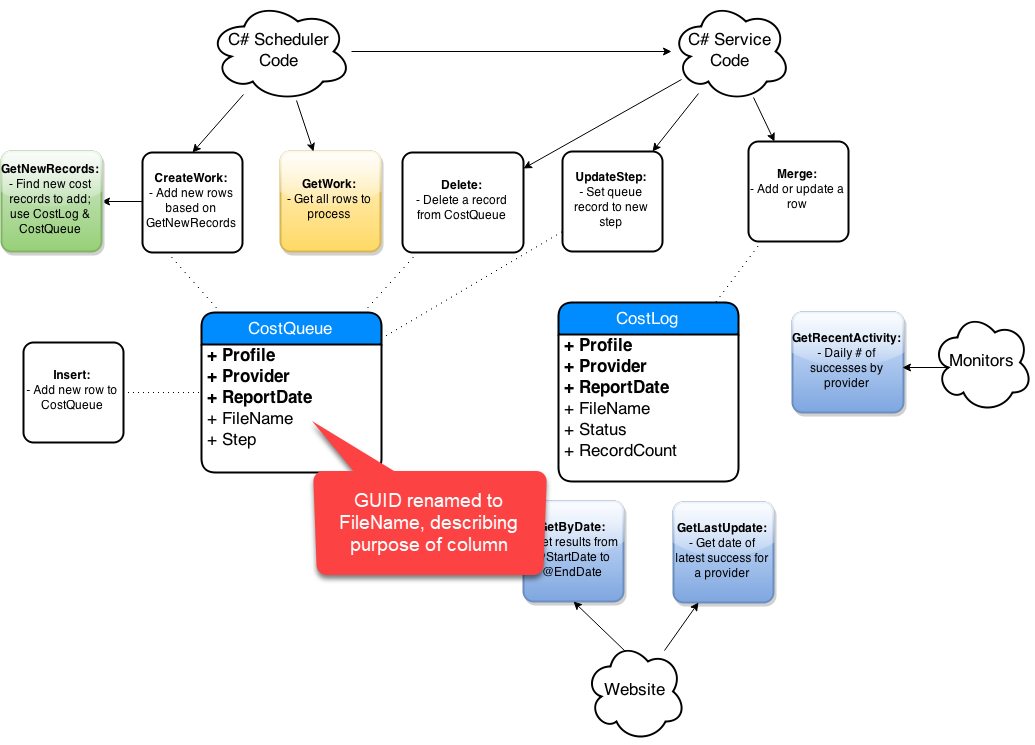
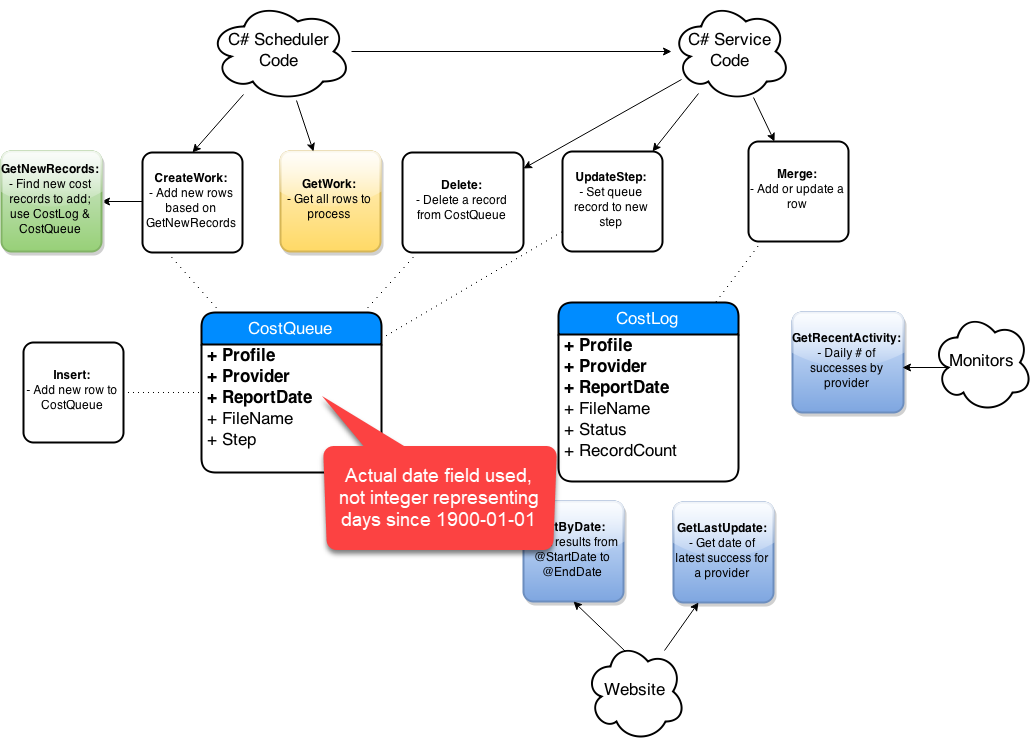
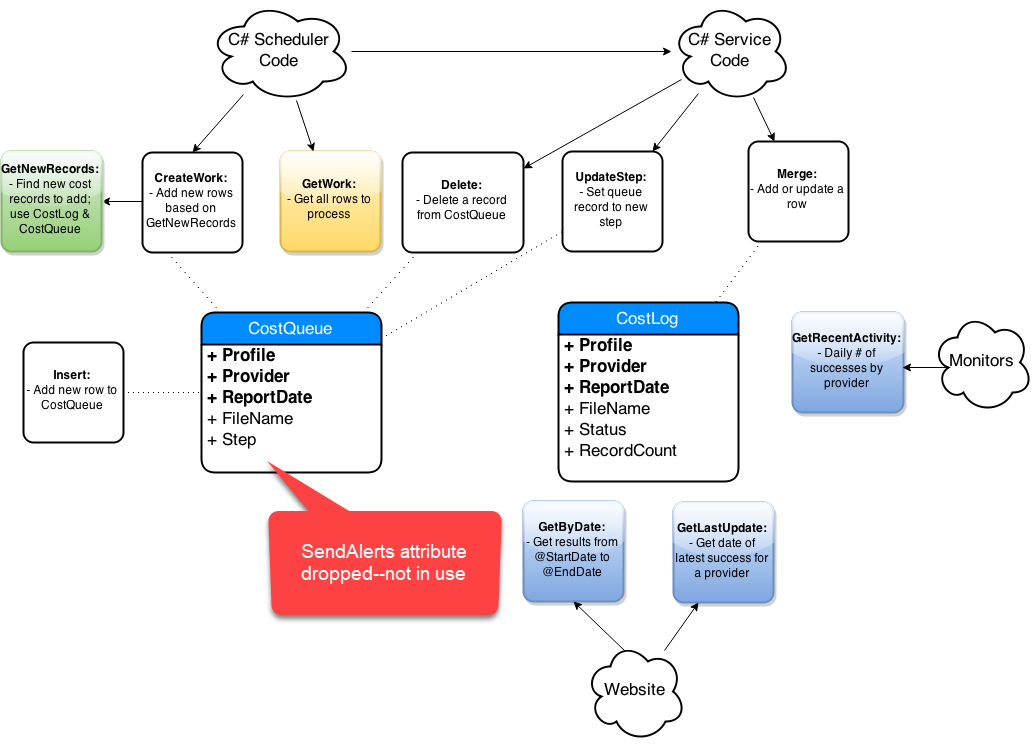
Step-By-Step Process
- Get list of affected objects
- Generate high-level diagram
- Document existing design
- Incremental changes on paper
- Collaborate: consumers and peers
- Iterate, iterate, iterate
- Simplify code in the new design
Agenda
- Prerequisites
- SQL Formatting
- Simplify Your Code
- Simplify Your Design
- Remove Obsolete Code
- Modernize Your Code
- Improve Durability and Visibility
Remove Obsolete Code
Code is a liability: every line of code requires somebody to maintain it; code takes time to parse, compile, interpret, or run; and more mental overhead for developers.
If that line of code is not solving a problem, get rid of it!
Example: eliminating 20% of the code base with zero effect on users
Demo Time
Remove Obsolete Code
We tend to hoard code, saving things "just in case." Instead of that, use source control and let a server hoard behind the scenes. Be aggressive in cleaning up code in comments or which is logically impossible.
Places to Look
- Plan cache and procedure cache
- SQL Agent jobs
- Searches in source control
- SSIS packages
- sys.sql_modules
Agenda
- Prerequisites
- SQL Formatting
- Simplify Your Code
- Simplify Your Design
- Remove Obsolete Code
- Modernize Your Code
- Improve Durability and Visibility
Modernization on the Small
Don't forget to take advantage of new functionality in SQL Server: window functions instead of cursors for running totals, data types like DATE, and functions like CONCAT to put together strings.
Demo Time
Modernization on the Large
- Review no-longer-relevant hardware constraints
- Review prior architectural decisions
- You've probably learned a lot since you wrote that code
- Review data requirements which have changed
Agenda
- Prerequisites
- SQL Formatting
- Simplify Your Code
- Simplify Your Design
- Remove Obsolete Code
- Modernize Your Code
- Improve Durability and Visibility
Improve Durability and Visibility
- Use TRY-CATCH to perform error handling
- Log database errors as they happen
- (Maybe) log metrics for queries
- Handle explicit transactions in a consistent manner
Demo Time
Improve Durability and Visibility
The net result from these changes is:
- Lots more code (mostly boilerplate and approximately fixed cost)
- Appropriate error handling and logging
- Visibility into performance metrics by parameter selection
- Transaction handling
Wrapping Up
Legacy code is painful. Get tests in place and refactor that code.
Also, be sure you are keeping up on major changes in T-SQL as you upgrade to newer versions of SQL Server.
Wrapping Up
To learn more, go here:
https://csmore.info/on/legacysql
And for help, contact me:
feasel@catallaxyservices.com | @feaselkl
Catallaxy Services consulting:
https://CSmore.info/on/contact